We are given an RGB image divided up into superpixels. We make the assumption that each superpixel represents approximately a flat surface in 3D space. We identify the plane in space the surface lies on, and then project the 2D pixels onto that plane in 3D.
We are able to infer the approximate 3D surface normal and position of a superpixel in our dataset using the depth data from the Kinect. Given that, we can classify each superpixel according to some orientation and location.
Classifier
We assign an orientation class (based on the estimated 3D surface normal) and a depth subclass. The 3D surface normal defines a plane somewhere in space. The depth subclass gives the distance of the plane from the origin.
We have 7 orientation classes. Because the camera in our training set rarely looks up or down, the floor and ceiling always have the same orientation, so we only need one class for each of them. However, walls in the scene can have any number of orientations, so we are currently giving 5 total classes for walls.
Orientation Classes Surface Normal
1 Up [0 1 0] (floors, tables, chair seats)
2 Down [0 -1 0] (ceiling)
3 Right [1 0 0] (walls)
4 Right-Center [1 0 -1]
5 Center [0 0 -1]
6 Left-Center [-1 0 -1]
7 Left [-1 0 0]
We have 10 total location subclasses for each orientation class. A location subclass gives us the distance from the plane to the origin, which tells us where the surface is in 3D space.
Features
To classify each superpixel, we are currently using a set of basic descriptors:
RGB mean XY mean
DOG (Difference of Gaussians) mean
Area
DOG histogram (6 bins)
RGB histogram (6 bins each)
The total number of dimensions of the feature vector is 31
We will then plug our feature vectors per superpixel and their classes into MultiBoost to get a single strong learner for the orientations, and then for each orientation we have a separate strong learner to get the location class.
We believe finding the location is a harder problem than finding the orientation. So it makes sense to make the location classification conditioned on the type of surface. The location of the 3D plane for ceiling and floors stays constant for most of the training images. We believe we will be able to classify ceiling and floors with higher confidence then walls.
Stitching Algorithm
The next step is to use a stitching algorithm that will iteratively perturb the superpixel surface normals and orientations from their estimated value, with the goal of piecing them together so they fit in 3D space. We will update this blog post to discuss this algorithm in more detail at a later time

1) Original image divided into 40 superpixels
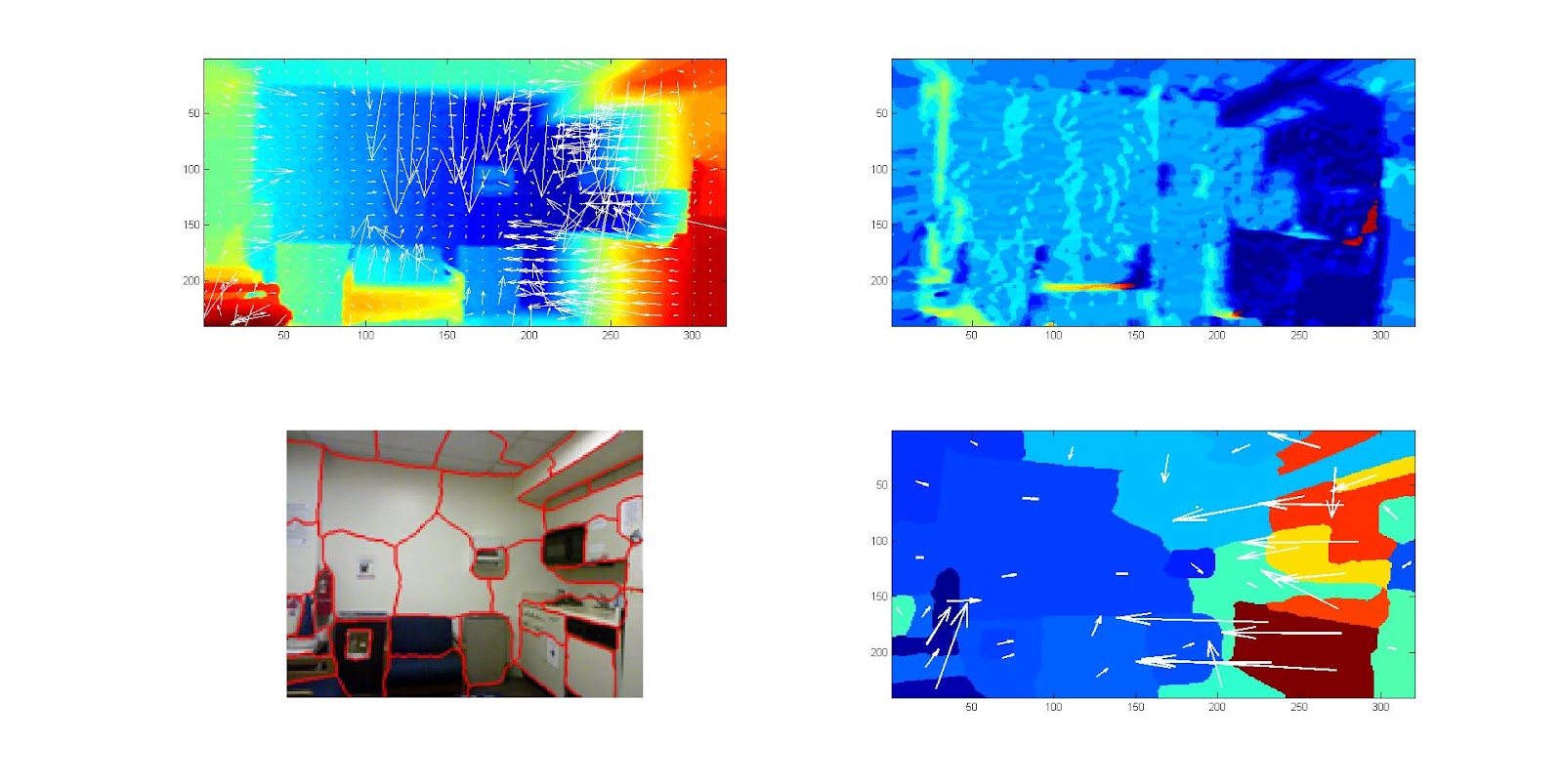
2) Depth map with per-pixel orientations
3) Superpixel location classes
4) Superpixel orientation classes
For the following images we show the point cloud result from projecting the superpixels onto their plane in 3D space. We show both the projection of the actual 3D location and normal estimated from the Kinect, and also the classified 3D location and normal.


The following images use a higher superpixel resolution of 200. Using a higher superpixel resolution, the popup model more closely resembles the actual model. However, this will also increase the computational complexity of our stitching algorithm (will be discussed later)


Finally, the highest superpixel resolution (1094):











.gif)







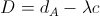.gif)
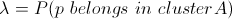
.gif)
(strawberries_fullcolor).tif)
{kind=link}
{kind=link}
{kind=link}
{kind=link}